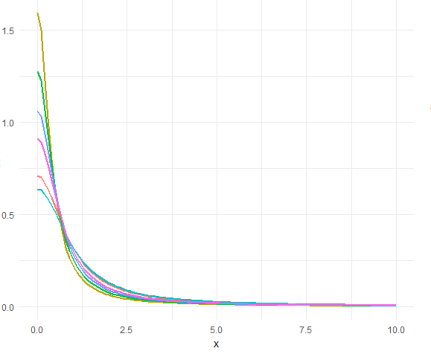
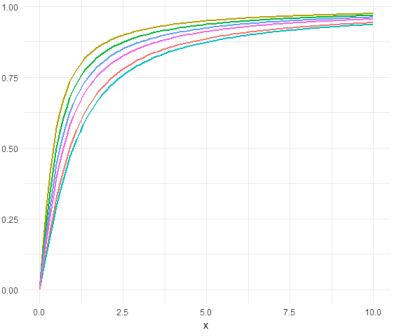
This paper introduces an innovative approach to modelling count data through the introduction of a robust quantile regression model, the Half Cauchy Quantile Regression (HCQR). Count data is frequently challenged by outliers and skewed distributions. By integrating the heavy-tailed properties of the Half Cauchy distribution into the quantile regression framework, the HCQR model offers reliable estimates, particularly in the presence of extreme values. Quantile regression models, including HCQR, typically exhibit greater robustness to such extremes compared to traditional methods. The study highlights the limitations of traditional count regression models, such as the Negative Binomial Regression (NBR), particularly their performance inadequacies within the quantile regression framework. A comparative analysis using real-world crime data illustrates that the HCQR model substantially outperforms the NBR model. By integrating the half Cauchy distribution into the quantile regression framework, the HCQR model was formulated. In the Half Cauchy Quantile Regression Model, the Half Cauchy quantile function is used to transform the traditional quantile regression outputs, accommodating the characteristics of the Half Cauchy distribution. This superiority is demonstrated through improved metrics such as lower Standard Deviation, Skewness, Kurtosis, Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC), establishing HCQR's enhanced robustness and predictive accuracy.
| Published in | Science Journal of Applied Mathematics and Statistics (Volume 13, Issue 2) |
| DOI | 10.11648/j.sjams.20251302.11 |
| Page(s) | 27-33 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Quantile Regression Model, Count Regression, Half Cauchy Distribution, Half Cauchy Quantile Regression Model, Robustness to Extreme Values
Model | MSE | RMSE | MAE | Skewness | Kurtosis | Standard Deviation | AIC | BIC | |
|---|---|---|---|---|---|---|---|---|---|
Negative Binomial Regression | 104.837 | 10.239 | 5.755 | 8.220 | 75.270 | 10.293 | 3004.587 | 3190.536 | |
Half Cauchy Quantile Regression | 0.05 | 95.969 | 9.796 | 3.147 | 7.245 | 68.616 | 9.289 | 2973.108 | 2993.066 |
0.25 | 96.044 | 9.800 | 3.190 | 7.218 | 68.284 | 9.283 | 2973.510 | 2993.467 | |
0.50 | 93.296 | 9.659 | 2.982 | 7.220 | 68.392 | 9.287 | 2960.729 | 2980.686 | |
0.75 | 91.823 | 9.582 | 2.862 | 7.248 | 68.688 | 9.286 | 2953.902 | 2973.859 | |
0.95 | 90.245 | 9.500 | 2.773 | 7.303 | 69.549 | 9.260 | 2946.694 | 2966.651 |
OLS | Ordinary Least Squares |
NBR | Negative Binomial Regression |
CQR | Cauchit Quantile Regression |
HCQR | Half Cauchy Quantile Regression |
MSE | Mean Square Error |
MAE | Mean Absolute Error |
RMSE | Root Mean Square Error |
AIC | Akaike Information Criteria |
BIC | Bayesian Information Criterion |
| [1] | Acquah, H. D. (2018). Comparing OLS and quantile regression estimation techniques for production analysis: An application to Ghanaian maize farms. RJOAS, 8(80), 388. |
| [2] | Allen, D. E., Gerrans, P., Powell, R., & Singh, A. K. (2009). Quantile regression: its application in investment analysis. Jassa, (4), 7-12. |
| [3] | Congdon, P. (2017). Quantile regression for overdispersed count data: A hierarchical method. Journal of Statistical Distributions and Applications, 4(18). |
| [4] | Francis, R. E., & Nwakuya, M. T. (2022). A comparative analysis of ordinary least squares and quantile regression estimation technique. American Journal of Mathematical and Computer Modelling, 7(4), 49-54. |
| [5] | Hao, L., & Naiman, D. Q. (2007). Quantile regression. SAGE Publications, Inc., |
| [6] | Koenker, R. (2004). Quantile regression for longitudinal data. Journal of Multivariate Analysis, 91(1), 74-89. |
| [7] | Koenker, R., & Bassett Jr, G. (1978). Regression quantiles. Econometrica: Journal of the Econometric Society, 46(1), 33-50. |
| [8] | Koenker, R., & Mizera, I. (2004). Penalized trigrams: Total variation regularization for bivariate smoothing. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 66(1), 145-163. |
| [9] | Korkmaz, M. Ç., Chesneau, C., & Korkmaz, Z. S. (2021). Transmuted unit Rayleigh quantile regression model: Alternative to beta and Kumaraswamy quantile regression models. UPB Scientific Bulletin, Series A: Applied Mathematics and Physics 83(3): 149-158. |
| [10] | Leiva, V., Sánchez, L., Galea, M., & Saulo, H. (2020). Birnbaum-Saunders quantile regression and its diagnostics with application to economic data. Applied Stochastic Models in Business and Industry, 36(5), 956-973. |
| [11] | Machado, J., & Santos Silva, J. (2005). Quantiles for counts. Journal of the American Statistical Association, 100(472), 1226-1237. |
| [12] | Mazucheli, J., Leiva, V., Alves, B., & Menezes, A. (2021). A new quantile regression for modeling bounded data under a unit Birnbaum–Saunders distribution with applications in medicine and politics. Symmetry, 13(4), 682. |
| [13] | Nwabueze, C. J., Onyegbuchulem, B. O, & Nwakuya, M. T. (2022). On the Equivariance of Location Reparameterization of Quantile Regression Model using Cauchy Transformation. Mathematical Theory and Modeling, 12(2), 2022. |
| [14] | Nwabueze, J. C., Onyegbuchulem, B. O., Nwakuya, M. T., & Onyegbuchulem, C. A. (2021). A Cauchy transformation approach to the robustness of quantile regression model to outliers. Royal Statistical Society Nigeria Local Group Conference Proceedings, 2021. |
APA Style
Francis, R. E., Nwakuya, M. T., Ijomah, M. A. (2025). A Robust Quantile Regression Model for Count Data: The Half Cauchy Transformation Approach. Science Journal of Applied Mathematics and Statistics, 13(2), 27-33. https://doi.org/10.11648/j.sjams.20251302.11
ACS Style
Francis, R. E.; Nwakuya, M. T.; Ijomah, M. A. A Robust Quantile Regression Model for Count Data: The Half Cauchy Transformation Approach. Sci. J. Appl. Math. Stat. 2025, 13(2), 27-33. doi: 10.11648/j.sjams.20251302.11
AMA Style
Francis RE, Nwakuya MT, Ijomah MA. A Robust Quantile Regression Model for Count Data: The Half Cauchy Transformation Approach. Sci J Appl Math Stat. 2025;13(2):27-33. doi: 10.11648/j.sjams.20251302.11
@article{10.11648/j.sjams.20251302.11,
author = {Runyi Emmanuel Francis and Maureen Tobe Nwakuya and Maxwell Azubuike Ijomah},
title = {A Robust Quantile Regression Model for Count Data: The Half Cauchy Transformation Approach
},
journal = {Science Journal of Applied Mathematics and Statistics},
volume = {13},
number = {2},
pages = {27-33},
doi = {10.11648/j.sjams.20251302.11},
url = {https://doi.org/10.11648/j.sjams.20251302.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.sjams.20251302.11},
abstract = {This paper introduces an innovative approach to modelling count data through the introduction of a robust quantile regression model, the Half Cauchy Quantile Regression (HCQR). Count data is frequently challenged by outliers and skewed distributions. By integrating the heavy-tailed properties of the Half Cauchy distribution into the quantile regression framework, the HCQR model offers reliable estimates, particularly in the presence of extreme values. Quantile regression models, including HCQR, typically exhibit greater robustness to such extremes compared to traditional methods. The study highlights the limitations of traditional count regression models, such as the Negative Binomial Regression (NBR), particularly their performance inadequacies within the quantile regression framework. A comparative analysis using real-world crime data illustrates that the HCQR model substantially outperforms the NBR model. By integrating the half Cauchy distribution into the quantile regression framework, the HCQR model was formulated. In the Half Cauchy Quantile Regression Model, the Half Cauchy quantile function is used to transform the traditional quantile regression outputs, accommodating the characteristics of the Half Cauchy distribution. This superiority is demonstrated through improved metrics such as lower Standard Deviation, Skewness, Kurtosis, Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC), establishing HCQR's enhanced robustness and predictive accuracy.
},
year = {2025}
}
TY - JOUR T1 - A Robust Quantile Regression Model for Count Data: The Half Cauchy Transformation Approach AU - Runyi Emmanuel Francis AU - Maureen Tobe Nwakuya AU - Maxwell Azubuike Ijomah Y1 - 2025/04/29 PY - 2025 N1 - https://doi.org/10.11648/j.sjams.20251302.11 DO - 10.11648/j.sjams.20251302.11 T2 - Science Journal of Applied Mathematics and Statistics JF - Science Journal of Applied Mathematics and Statistics JO - Science Journal of Applied Mathematics and Statistics SP - 27 EP - 33 PB - Science Publishing Group SN - 2376-9513 UR - https://doi.org/10.11648/j.sjams.20251302.11 AB - This paper introduces an innovative approach to modelling count data through the introduction of a robust quantile regression model, the Half Cauchy Quantile Regression (HCQR). Count data is frequently challenged by outliers and skewed distributions. By integrating the heavy-tailed properties of the Half Cauchy distribution into the quantile regression framework, the HCQR model offers reliable estimates, particularly in the presence of extreme values. Quantile regression models, including HCQR, typically exhibit greater robustness to such extremes compared to traditional methods. The study highlights the limitations of traditional count regression models, such as the Negative Binomial Regression (NBR), particularly their performance inadequacies within the quantile regression framework. A comparative analysis using real-world crime data illustrates that the HCQR model substantially outperforms the NBR model. By integrating the half Cauchy distribution into the quantile regression framework, the HCQR model was formulated. In the Half Cauchy Quantile Regression Model, the Half Cauchy quantile function is used to transform the traditional quantile regression outputs, accommodating the characteristics of the Half Cauchy distribution. This superiority is demonstrated through improved metrics such as lower Standard Deviation, Skewness, Kurtosis, Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC), establishing HCQR's enhanced robustness and predictive accuracy. VL - 13 IS - 2 ER -
Department of Statistics, Federal Polytechnic Ugep, Ugep, Nigeria
Department of Mathematics and Statistics, University of Port Harcourt, Port Harcourt, Nigeria
Department of Mathematics and Statistics, University of Port Harcourt, Port Harcourt, Nigeria